Loading project...
Other
Research study comparing how CNNs and Vision Transformers represent GAN and diffusion-generated images.
This project investigates how modern generative image models, including GANs and diffusion models, are represented inside deep neural networks, with the goal of understanding how to better distinguish between real and synthetic images.
The study analyzes images from multiple generators alongside real and forged samples using three backbone architectures: ResNet-50, Xception, and Vision Transformer (ViT). Each model captures different aspects of the image, from local textures to global semantic structure.
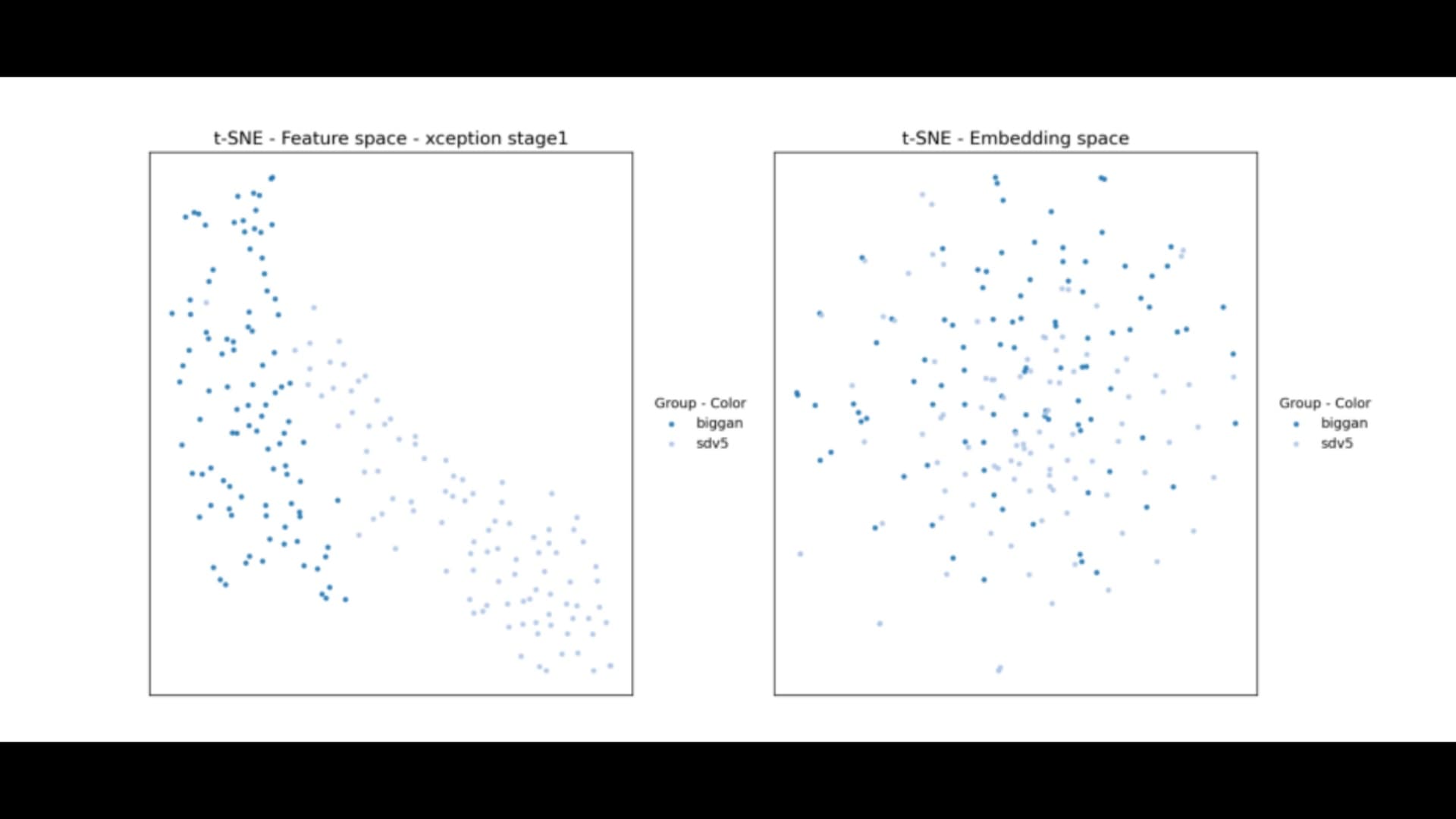
A key focus of the project is comparing two representation spaces. The embedding space provides a compact global representation, while intermediate feature maps preserve rich spatial and structural information. Through visualization and analysis, the results show that embeddings tend to overlap across different generators, while feature maps provide clearer separation.
Additional experiments demonstrate that early convolutional feature maps are highly discriminative and retain important fine-grained artifacts, while deeper representations become more abstract and less informative for this task.
Overall, the findings highlight that spatially rich representations are more effective than compact embeddings for detecting generative artifacts, providing insights for building more robust deepfake detection and image forensics systems.
Sign in to leave a comment